

In a single week in April 2026, Anthropic shipped Claude Opus 4.7, launched a new product called Claude Design, and added Routines that run even when your laptop is closed.
On the same day, OpenAI ratcheted up Codex with parallel agents that click and type on your Mac.
This is normal now. April 2026 has been called one of the most packed month for LLM releases on record. Roughly 65–70% of enterprise code is AI-written. Over 50% of companies describe their AI adoption as a "chaotic free-for-all."
And yet the most-starred developer resource in this entire space isn't a framework, a plugin, or a model.
It's four sentences in a markdown file.
One GitHub repo. 60,000 stars.
No dependencies, no API, no build step.
Just a CLAUDE.md file with four behavioral guidelines derived from something Andrej Karpathy posted in January. What 60,000 developers bookmarked tells you more about the real bottleneck in AI-assisted coding than any product announcement this week.
I spent last weekend migrating my own CLAUDE.md to work better with the latest Claude Code update. Forty-seven rules, carefully accumulated over months. The agent ignored half of them and hallucinated conventions I never wrote. That's when I found this repo. And that's when I realized the problem wasn't my rules. It was how many I had.
What Karpathy Actually Diagnosed
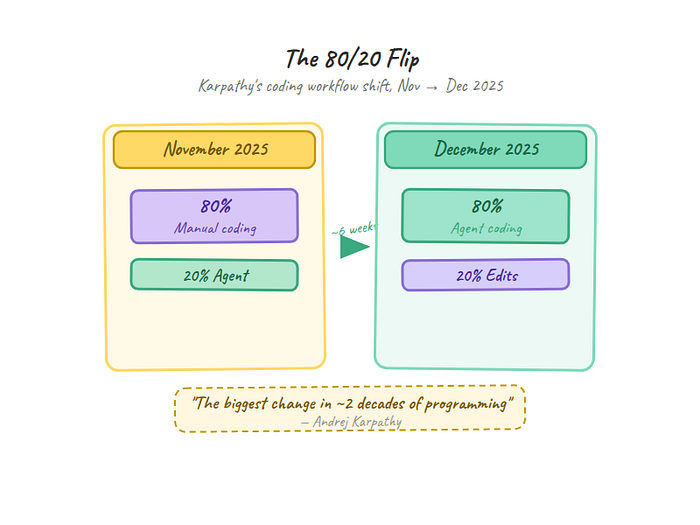
In January 2026, Andrej Karpathy posted a thread that landed differently than most AI commentary. He wasn't announcing anything. He was describing what broke.
Over roughly six weeks, from November to December 2025, he'd gone from 80% manual coding with 20% agent assist to the complete inverse. 80% agent, 20% edits. He called it "easily the biggest change in ~2 decades of programming." But the thread wasn't celebratory. It was diagnostic.
The models weren't failing at code. They were failing at judgment.
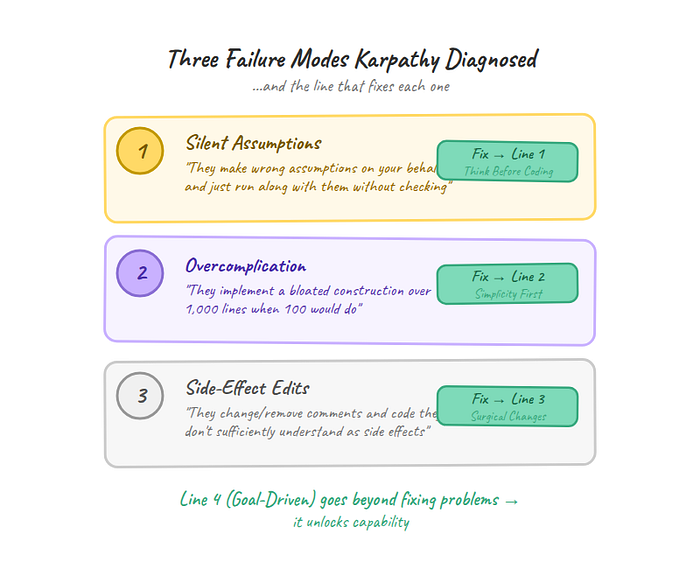
"The models make wrong assumptions on your behalf and just run along with them without checking." Karpathy nailed the deeper issue: "They don't manage their confusion, don't seek clarifications, don't surface inconsistencies, don't present tradeoffs, don't push back when they should."
You ask for "export user data" and the agent assumes JSON, writes to disk, includes every field, skips pagination. It never stops to say "I'm not sure which format you want." It just picks and runs.
This is where Line 1 comes from.
"They really like to overcomplicate code and APIs, bloat abstractions." Karpathy's version: they "implement a bloated construction over 1,000 lines when 100 would do."
You ask for a discount calculator and get a Strategy pattern with abstract base classes, an enum, a dataclass config, and 40 lines of setup. The agent builds for tomorrow's requirements instead of today's problem.
This maps directly to Line 2.
"They still sometimes change/remove comments and code they don't sufficiently understand as side effects, even if orthogonal to the task."
You ask the agent to fix a bug, and the PR also reformats your quotes from single to double, adds type hints you didn't ask for, and rewrites adjacent code. The fix was 3 lines. The diff is 40.
Line 3 exists because of this.
The thread resonated because it wasn't prescriptive. Karpathy didn't offer solutions. He described the failure modes clearly enough that within days, someone translated them into a four-line CLAUDE.md file and published it on GitHub.
But there's a fourth line that goes beyond discipline into something Karpathy himself hinted at: "LLMs are exceptionally good at looping until they meet specific goals. Don't tell it what to do. Give it success criteria and watch it go."
That's Line 4. And it's the one that makes the whole thing more than a style guide.
The 4 Lines
Here they are. The complete behavioral section of a CLAUDE.md file that 55,000 developers decided was worth starring:
1. Don't assume. Don't hide confusion. Surface tradeoffs.
2. Minimum code that solves the problem. Nothing speculative.
3. Touch only what you must. Clean up only your own mess.
4. Define success criteria. Loop until verified.
That's the whole thing. Each line maps directly to one of Karpathy's failure modes:

Let's break down why each one works. The before/after examples below are adapted from the repo's EXAMPLES.md, which has full walkthroughs for each principle.
Think Before Coding: Don't assume. Don't hide confusion. Surface tradeoffs.
This is the one that fixes the most common frustration with AI coding agents: they guess when they should ask.
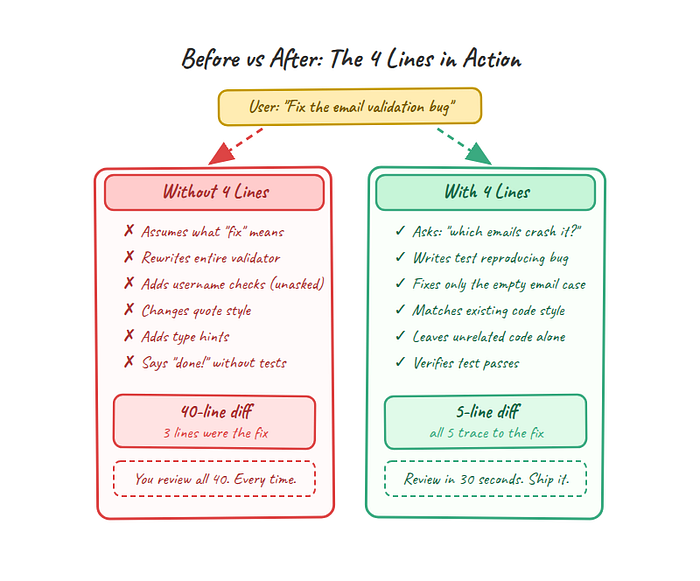
Without this line, here's what happens when you tell an agent "add a feature to export user data":
def export_users(format='json'):
users = User.query.all()
if format == 'json':
with open('users.json', 'w') as f:
json.dump([u.to_dict() for u in users], f)
return f"Exported {len(users)} users"The agent assumed JSON. Assumed all users. Assumed file output to disk. Assumed which fields to include. It never mentioned any of these decisions. It just picked and kept going.
With this principle, the agent's first response looks like this instead:
Before implementing, I need to clarify:
1. Scope: Export all users or a filtered subset?
2. Format: JSON download, CSV file, or API endpoint?
3. Fields: Which user fields? Some might be sensitive.
4. Volume: How many users? (affects the approach)Four questions instead of four assumptions. The code comes after the answers, not before them.
Why this matters more than it looks: LLMs don't naturally externalize uncertainty. They're trained on completion, not on pausing. Every token in their training data moves forward. Stopping to say "I'm not sure" goes against the grain of how these models learned to generate text. This line forces a behavior the model has the capability for but doesn't default to. It's not adding a feature. It's overriding a default.
Simplicity First: Minimum code that solves the problem. Nothing speculative.
This kills premature abstraction. Without it, you ask for "a function to calculate a discount" and get this:
class DiscountStrategy(ABC):
@abstractmethod
def calculate(self, amount: float) -> float:
pass
class PercentageDiscount(DiscountStrategy):
def __init__(self, percentage: float):
self.percentage = percentage
def calculate(self, amount: float) -> float:
return amount * (self.percentage / 100)
class FixedDiscount(DiscountStrategy):
# ... 20 more lines
class DiscountCalculator:
def __init__(self, config: DiscountConfig):
# ... 15 more lines of setupAbstract base class. Strategy pattern. Config dataclass. Forty-plus lines for arithmetic.
With this principle:
def calculate_discount(amount: float, percent: float) -> float:
return amount * (percent / 100)One function. One line of logic. If you need the Strategy pattern later, refactor then. Not now. Not speculatively.
Here's the insight most articles miss: the overcomplicated version isn't obviously wrong. It follows real design patterns. A senior engineer might actually use the Strategy pattern in a large billing system. The problem is timing. Premature abstraction has a cost that compounds: more code means more surface area for bugs, more cognitive load for reviewers, and more inertia when you need to change direction. The agent builds for requirements that don't exist yet and may never exist. Good code solves today's problem simply, not tomorrow's problem prematurely.
The senior engineer test from the original file nails it: "Would a senior engineer say this is overcomplicated?" If yes, simplify.
Surgical Changes: Touch only what you must. Clean up only your own mess.
This one protects your diffs. You ask the agent to fix a bug where empty emails crash the validator. Without this principle, the diff looks like this:
- if not user_data.get('email'):
+ email = user_data.get('email', '').strip()
+ if not email:
raise ValueError("Email required")
- if '@' not in user_data['email']:
+ if '@' not in email or '.' not in email.split('@')[1]:
raise ValueError("Invalid email")
- if not user_data.get('username'):
+ username = user_data.get('username', '').strip()
+ if not username:
raise ValueError("Username required")
+ if len(username) < 3:
+ raise ValueError("Username too short")
+ if not username.isalnum():
+ raise ValueError("Username must be alphanumeric")The bug fix was the empty email handling. The agent also "improved" email validation, added username length checks, added alphanumeric enforcement, and changed variable names. None of that was requested.
With this principle, the diff is surgical:
- if not user_data.get('email'):
+ email = user_data.get('email', '')
+ if not email or not email.strip():
raise ValueError("Email required")
- if '@' not in user_data['email']:
+ if '@' not in email:
raise ValueError("Invalid email")Every changed line traces to the bug report. Nothing else.
The real unlock here isn't cleanliness. It's auditability. When an agent's diff contains 40 lines and only 3 trace to the request, you can't trust the other 37 without reviewing each one individually. That's not a minor annoyance. It's a review tax on every piece of AI-generated code. Surgical changes make AI output reviewable at the speed you actually need. The smaller the diff, the faster you can trust it, merge it, and move on.
The original file adds a subtle but important nuance: if YOUR changes create orphans (unused imports, dead variables), clean those up. But don't touch pre-existing dead code unless asked. Your mess, your cleanup. Their mess, their decision.
Goal-Driven Execution: Define success criteria. Loop until verified.
The first three principles are guardrails. They constrain behavior. This one is different. It's a capability unlock.
This is the principle that turns Karpathy's observation into leverage. He noticed that LLMs are "exceptionally good at looping until they meet specific goals." The problem isn't that agents can't iterate. It's that we give them vague instructions instead of verifiable targets.
Without this principle, you say "fix the authentication system" and the agent responds:
I'll fix the authentication system by:
1. Reviewing the code
2. Identifying issues
3. Making improvements
4. Testing the changesVague plan. No success criteria. No verification. It'll change something and call it done.
With this principle, the same request transforms:
1. Write test: password change → old session invalidated
→ Verify: test fails (reproduces bug)
2. Implement: invalidate sessions on password change
→ Verify: test passes
3. Edge cases: multiple sessions, concurrent changes
→ Verify: additional tests pass
4. Regression: existing auth tests still pass
→ Verify: full test suite greenEach step has a check. The agent can loop independently because it knows what "done" looks like. Strong success criteria replace constant hand-holding.
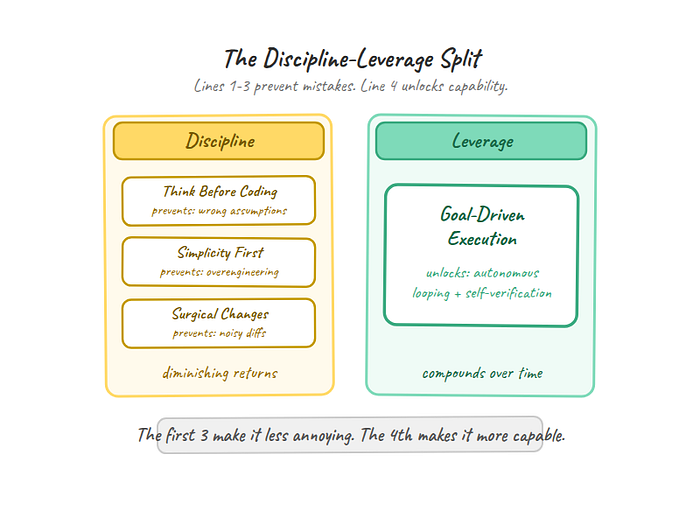
Here's what separates this principle from the other three: Think Before Coding, Simplicity First, and Surgical Changes are discipline. They prevent bad behavior. Goal-Driven Execution is leverage. It unlocks behavior the agent is already good at but doesn't activate without the right prompt structure. The first three principles make the agent less annoying. The fourth makes it more capable. And that distinction matters. Discipline has diminishing returns. Leverage compounds.
One caveat: these examples show clean single-file tasks. I'd want to see how the 4 lines hold up on a 100K-line monorepo with multiple teams and tangled dependencies. Single-developer projects are the easy case. The harder question is whether behavioral guidelines alone can scale to the complexity that most enterprise codebases actually have.
The Configuration Paradox
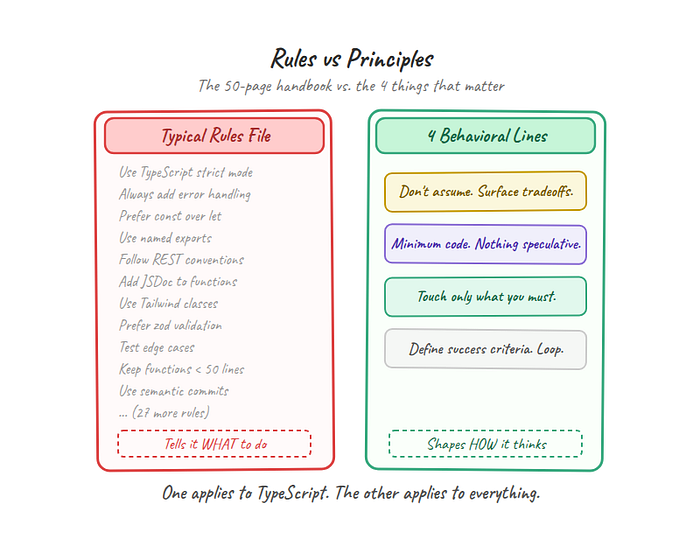
The natural instinct when an AI agent misbehaves is to add more rules. Don't use semicolons. Always add error handling. Follow the repository's naming convention. Prefer functional patterns. Use TypeScript strict mode.
This instinct has produced an ecosystem that's staggering in scope. One popular GitHub toolkit lists 135 agents, 35 curated skills, 400,000+ skills via marketplace, 176 plugins, and 42 commands. Another offers 30 specialized agents and 136 skills. There are now at least five competing config formats: CLAUDE.md, AGENTS.md, .cursorrules, copilot-instructions.md, and .windsurfrules. There's even a tool to convert rules between formats.
The ecosystem has more configuration options than most teams have engineers.
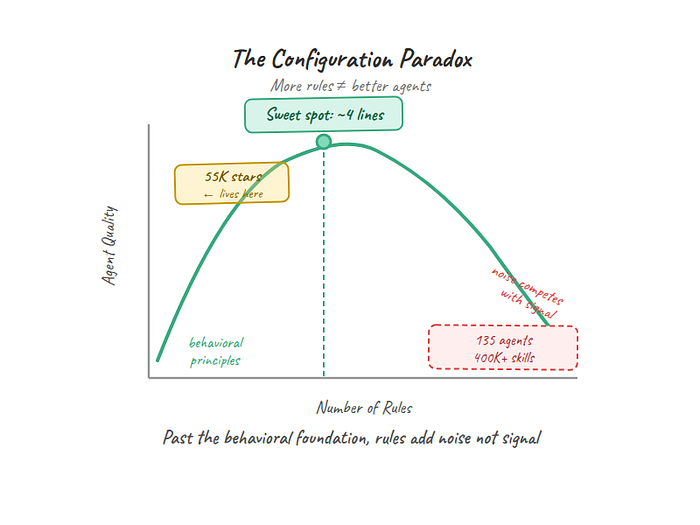
Here's the problem: it doesn't scale the way you'd expect. Claude Code caps individual rule files at 6,000 characters and total combined rules at 12,000. Those limits exist for a reason. Past a certain threshold, adding rules produces confused agents, not disciplined ones. Anthropic's own docs say it plainly: "For each line, ask: 'Would removing this cause Claude to make mistakes?' If not, cut it."
Think of it like onboarding a new hire. You can hand them a 50-page employee handbook covering every possible scenario. Or you can tell them four principles the company actually lives by and trust them to apply judgment. The handbook gets filed in a drawer. The principles get used.
That's the Configuration Paradox: more rules feel like more control, but past the behavioral foundation, they add noise that competes with signal. The 55,000 stars aren't a vote for minimalism as an aesthetic. They're a vote for the insight that behavioral constraints outperform feature checklists.
The 4 lines work because they shape how the agent thinks, not what it does. They're transferable across projects, languages, and problem types. A rule like "use TypeScript strict mode" applies to one stack. "Don't assume" applies to everything.
What to Actually Put in Your File
The fastest path: just install the file directly from the repo that started this.
Option A: Claude Code Plugin (recommended)
From within Claude Code, add the marketplace and install:
/plugin marketplace add forrestchang/andrej-karpathy-skills
/plugin install andrej-karpathy-skills@karpathy-skillsThis makes the guidelines available across all your projects automatically.
Option B: Download the file directly
New project:
curl -o CLAUDE.md https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.mdExisting project (append to your current file):
echo "" >> CLAUDE.md
curl https://raw.githubusercontent.com/forrestchang/andrej-karpathy-skills/main/CLAUDE.md >> CLAUDE.mdThe full file expands each of the 4 principles with sub-bullets and examples. But the core is still those four one-liners. Everything else is elaboration.
Once the behavioral foundation is in place, add a thin layer of project-specific context on top. Not rules about how to code. Context the agent can't infer by reading your files.
Build commands. The agent needs to know how to run your project:
## Project
- Build: `npm run build`
- Test: `npm test`
- Lint: `npm run lint -- --fix`Conventions the code doesn't show. Decisions that aren't visible in the existing code:
## Conventions
- API errors return { error: string, code: number }, never throw
- All dates stored as UTC, displayed in user's timezone
- Feature flags live in config/flags.ts, not inlineLessons from past failures. One-line reminders about things that broke before:
## Watch out
- The payments service timeout is 30s, not the default 5s
- Don't import from /internal -- it breaks the public API build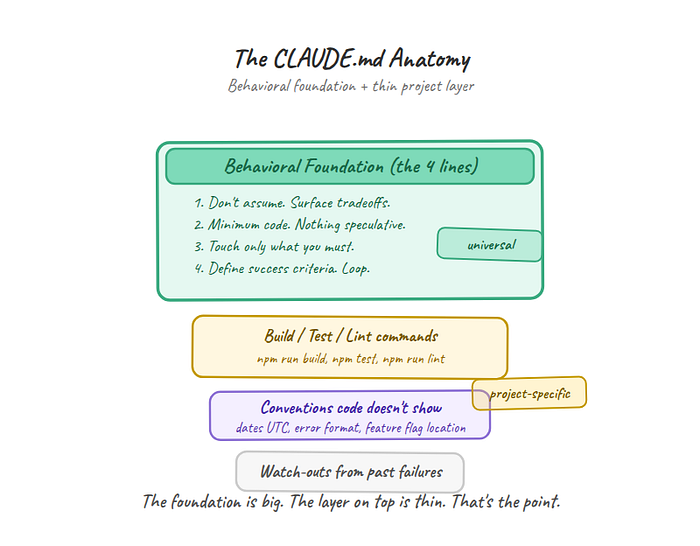
That's it. Behavioral foundation from the repo, build commands, a few conventions, maybe a warning. The litmus test for every line you add beyond the 4: "Would removing this cause the agent to make a mistake it couldn't recover from?" If the answer is no, leave it out.
What NOT to put in your file: architecture overviews the agent can read from the code, style guides it can infer from existing patterns, dependency lists it can find in package.json, or documentation it can access through your repo. The agent reads your codebase. Don't duplicate what's already there.
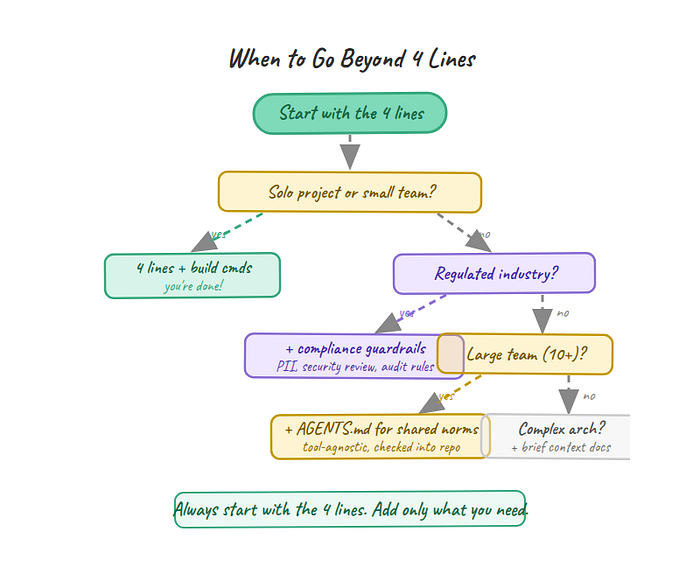
Where 4 Lines Aren't Enough
These guidelines handle the behavioral layer well. But behavior isn't the only layer.
Complex multi-file refactors. When you're restructuring an entire module, moving functions across files, and updating import chains, the agent needs architectural context that behavioral constraints can't provide. "Don't assume" won't help if the agent doesn't know which files depend on what. For large refactors, you need to add a brief architecture section to your CLAUDE.md or break the work into smaller, well-scoped tasks the agent can handle one at a time.
Regulated industries. If you work in healthcare, fintech, or anything with compliance requirements, four behavioral lines won't cover "never log PII" or "all API changes require security review." Domain-specific guardrails are a separate concern from behavioral guidelines. Add them alongside the 4 lines, not instead of them.
Team-scale consistency. One developer's CLAUDE.md is straightforward. Getting 20 engineers to share behavioral norms for their agents is a coordination problem, not a configuration problem. That's where formats like AGENTS.md (checked into the repo, tool-agnostic) start to matter. The 4 lines are a starting point for teams, but teams also need agreement on which project-specific rules sit on top.
Tool portability. These guidelines were written for Claude Code specifically. Cursor, Copilot, and Codex have overlapping but different failure modes. The principles transfer. "Don't assume" is good advice regardless of which agent you're using. But the specific phrasing and how much the agent responds to it will vary by tool. If you're on Cursor, you'll need to adapt these for .cursorrules format and test whether the agent interprets them the same way.
One more honest note: the 60,000 stars are a signal of resonance, not proof of efficacy. We don't have rigorous before/after benchmarks showing exactly how much these guidelines improve output quality. One site claims 94% accuracy with the Karpathy guidelines, but I'd want to see the methodology before treating that as a definitive number. What we have is strong anecdotal consensus from a large developer population. That's meaningful, but it's not a controlled study.
The Behavioral Bottleneck
60,000 stars on a text file tells you something the product announcements don't: the bottleneck in AI-assisted coding was never capability. It was behavior.
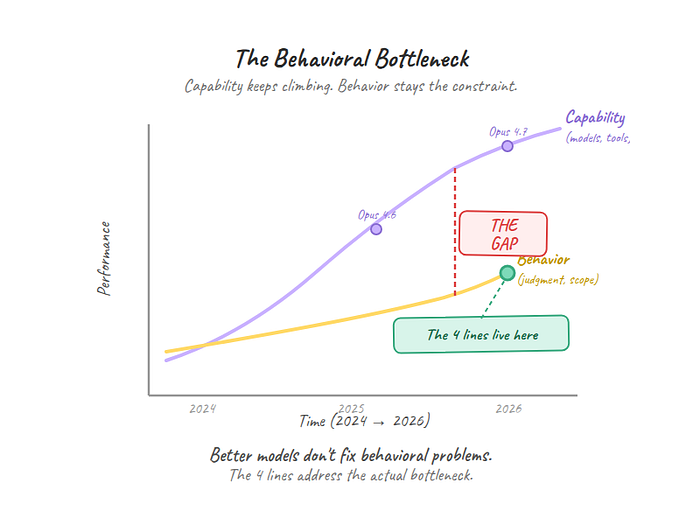
The models can write code. They've been able to write code for a while now. What they can't do reliably is decide when to stop writing, what to ask before starting, how much to change, and how to verify they're done. Those are behavioral problems, not intelligence problems. And behavioral problems don't get solved by making the model smarter. They get solved by telling the model how to act.
That's why four sentences outperformed an ecosystem of plugins, agents, and skills. Not because the ecosystem is wrong. It isn't. But it's solving the capability layer while the behavioral layer remains the binding constraint.
Every model improvement helps. But until agents reliably manage their own uncertainty, scope their own changes, and verify their own work, the 4 lines will keep doing more per character than any feature announcement.
Here's what I'd actually change in my workflow tomorrow: open my CLAUDE.md, strip out every rule the agent could figure out by reading the codebase, add the 4 behavioral lines if they're not already there, and judge every future rule I'm tempted to add by one question: does this shape how the agent thinks, or just what it does? If it's the latter, it probably doesn't belong in the file.
If you want to go deeper, the repo's EXAMPLES.md has full before/after code walkthroughs for each principle, including multi-step verification patterns for Line 4.
The models will keep getting smarter. The tools will keep getting more powerful. The bottleneck will stay behavioral until the models learn to manage their own judgment. And until then, four sentences in a markdown file will keep outperforming the product launch cycle.
Before you go! 🦸🏻♀️
If you liked my story and you want to support me:
- Throw some Medium love 💕(claps, comments and highlights), your support means the world to me.👏
- Follow me on Medium and subscribe to get my latest article🫶