


From Conspiracy to Receipts
Yes, the title sounds like a conspiracy theory.
But let me say in plain words what they refuse to admit: they are trying to reach the moon by building a taller ladder, scaling flat transformers, throwing hundreds of billions of dollars a year in brute-force computation at a problem the architecture cannot solve at any cost.
Meanwhile they hide the blueprint they are actually working on, the rocket ship that is Geometric AI, which would save trillions by handing out the whole map instead of one street address at a time.
Of course they are telling you the opposite story. The core of it is much simpler than the trillion-dollar price tag suggests: at the heart of current AI sits a geometrical problem, and no GPU farm in the world is going to fix it, not even with the nuclear-powered data center the size of Patagonia they have started building.
Stay with me. Because you will see how this apparently crazy absurdity has a point of sanity hidden inside the labs themselves: their research teams are following a different approach to the sola computatione of the current AI church.
The smoking gun is neither a secret server farm nor a leaked memo. And least of all, it is not some cinematic superintelligence hidden behind a locked door. It is something much colder and more practical.
The back door is inside the technical and scientific papers of the companies themselves, which, except for some expert nerds, almost nobody outside the field reads.
Do you want to find out whether NVIDIA, Google, Anthropic, and the rest are selling the opposite of what they are intensively researching? Then don't read their press releases, their stage-managed public events, or the effusive declarations of their CEOs. Do something far simpler: grab the research papers of their fringe teams, and you will see where this story begins and how it drives into a new territory of AI that should set off alarms for you.
Don't worry. I have done the homework for you. Here we go.
We Should Already Have a Truly Non-Parroting AI
But first, let me be precise about what is under attack in current AI.
Ok, we have already mentioned transformers. Sure, they have positional encoding. They have attention. They mix each token with the tokens around it across many layers of computation. They are not blind to context in the trivial sense; anyone arguing that they are has not opened the 2017 paper.
The legitimate attack is not that AI is blind.
The legitimate attack is that the current architecture handles context in a structurally wrong way, and scaling computation cannot truly fix it.
Attention layered on top of flat embedding spaces does not, by itself, measure the semantic distance between concepts that overlap and shift with context.
Take justice and law as a worked example.
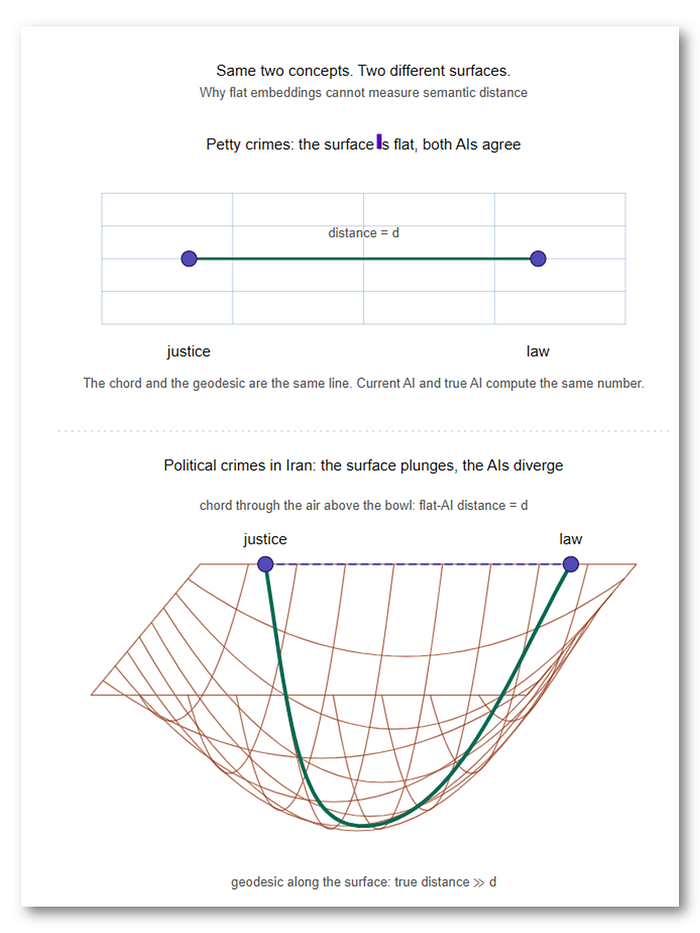
The distance between these two concepts in the democratic United States and in the theocracy of Iran may look almost identical when you are talking about petty crimes and ordinary civil offenses. But the moment you move to political crimes, the two concepts can sit at opposite ends of the semantic space.
Same two concepts, yeah, but…
Different distance.
Different context.
That is the point.
Meaning is not just a word sitting near another word. Meaning is a position inside a changing semantic terrain. The distance between concepts depends on the background against which they are read.
Flat AI embeddings cannot do this for free. They force the model to fake it by feeding it enough examples to memorize how the distance shifts: different regimes, different offenses, different legal traditions, endless combinations. Brute statistical memorization where geometry should be doing the work.
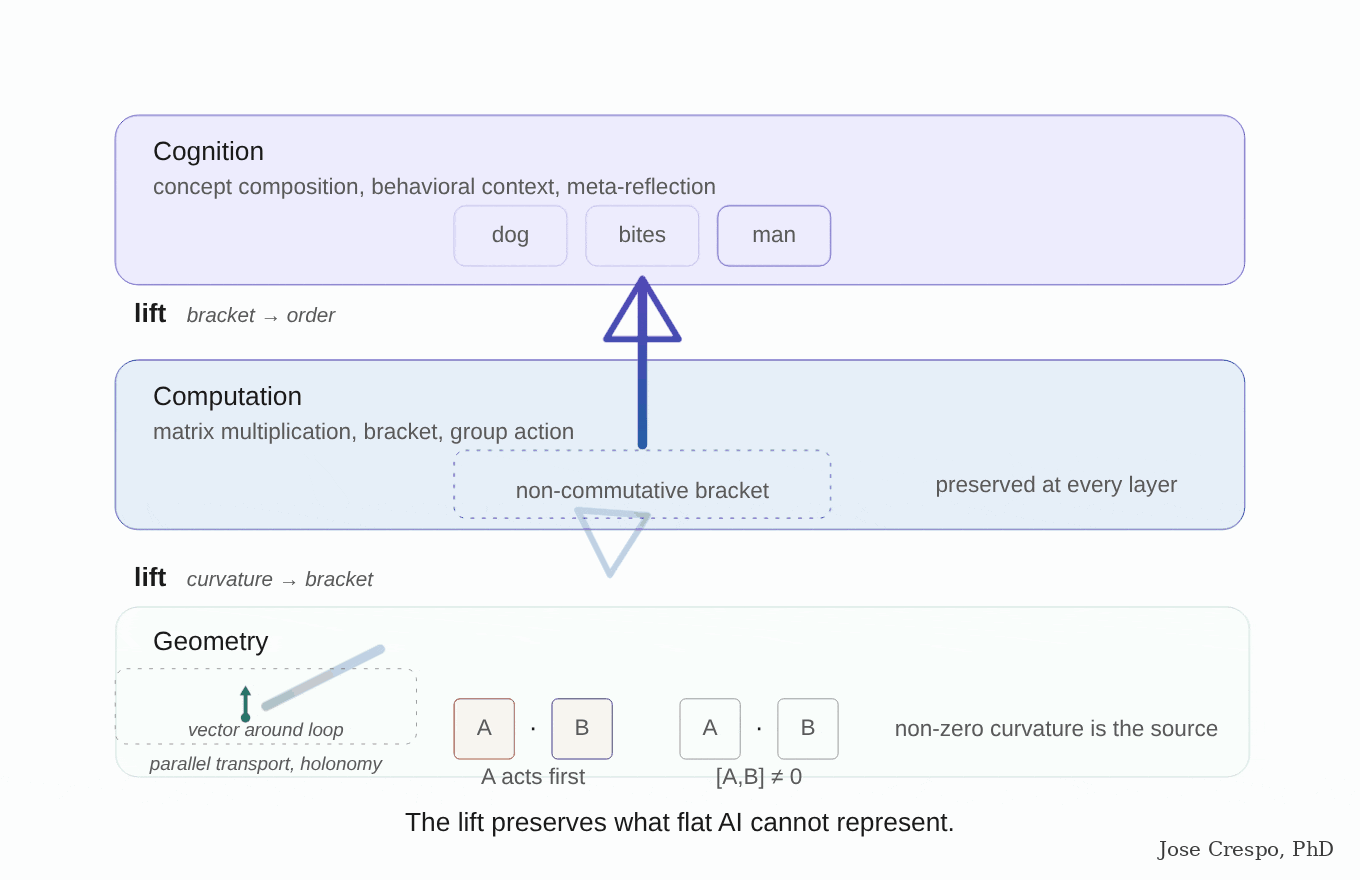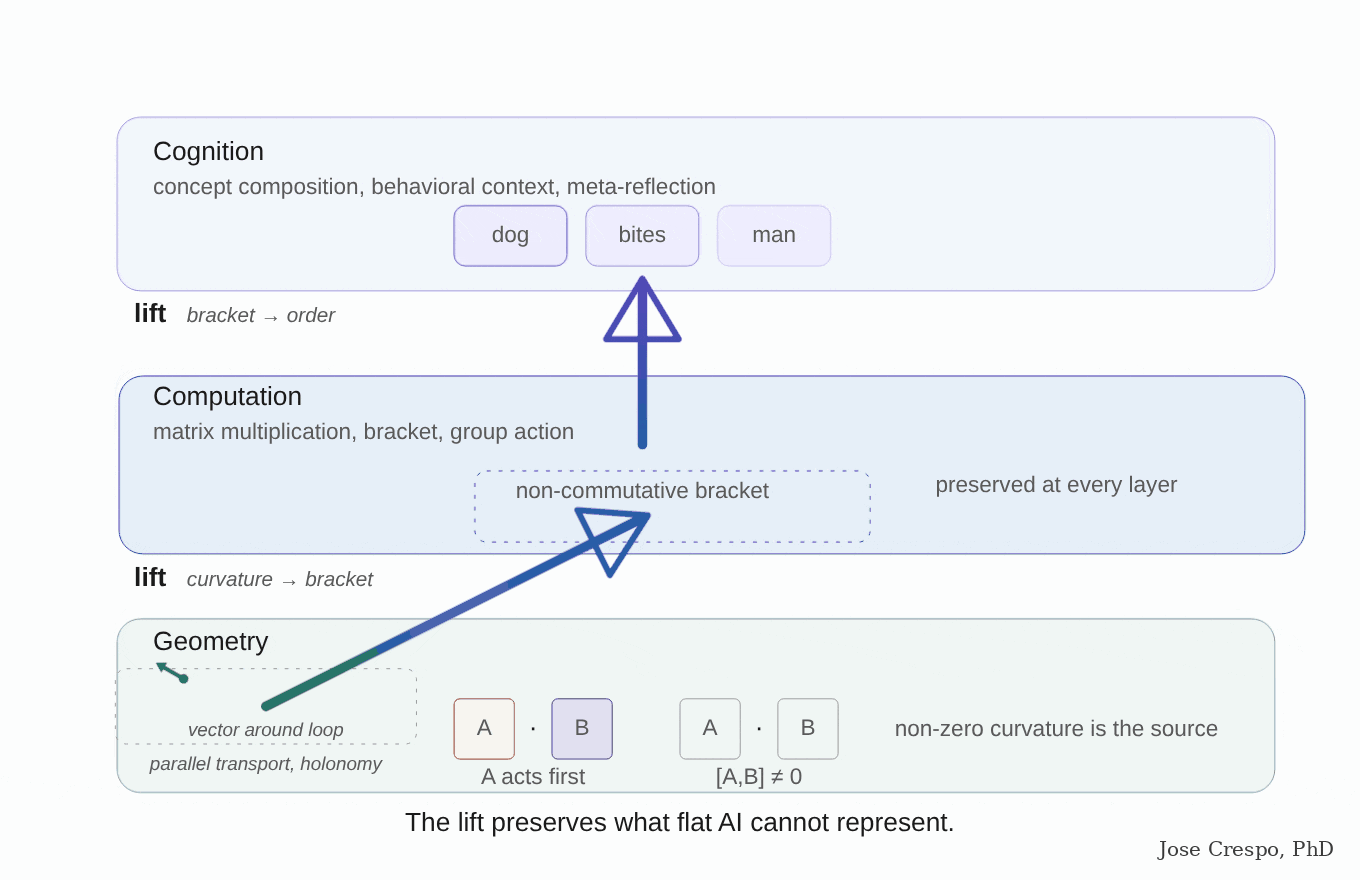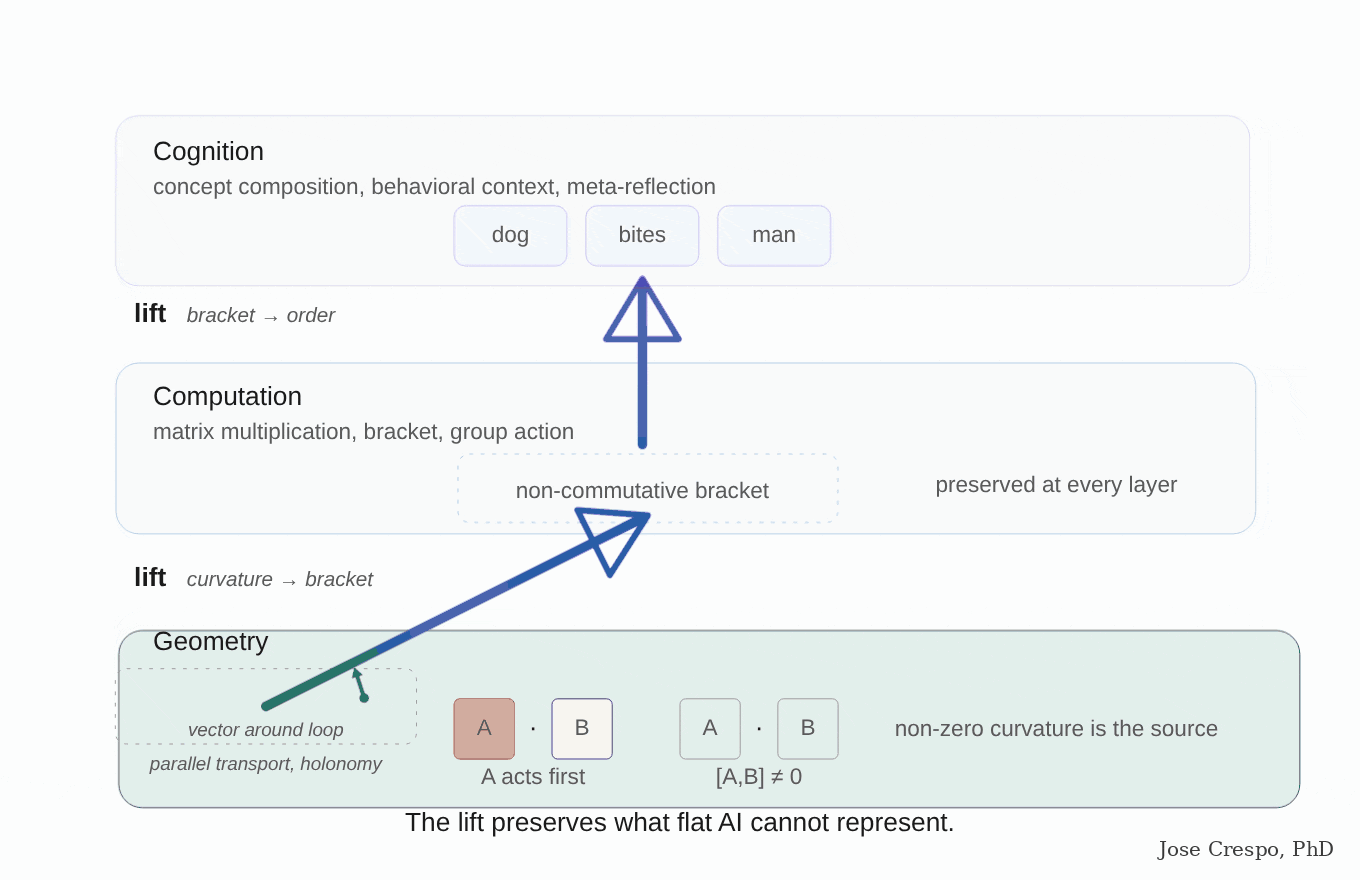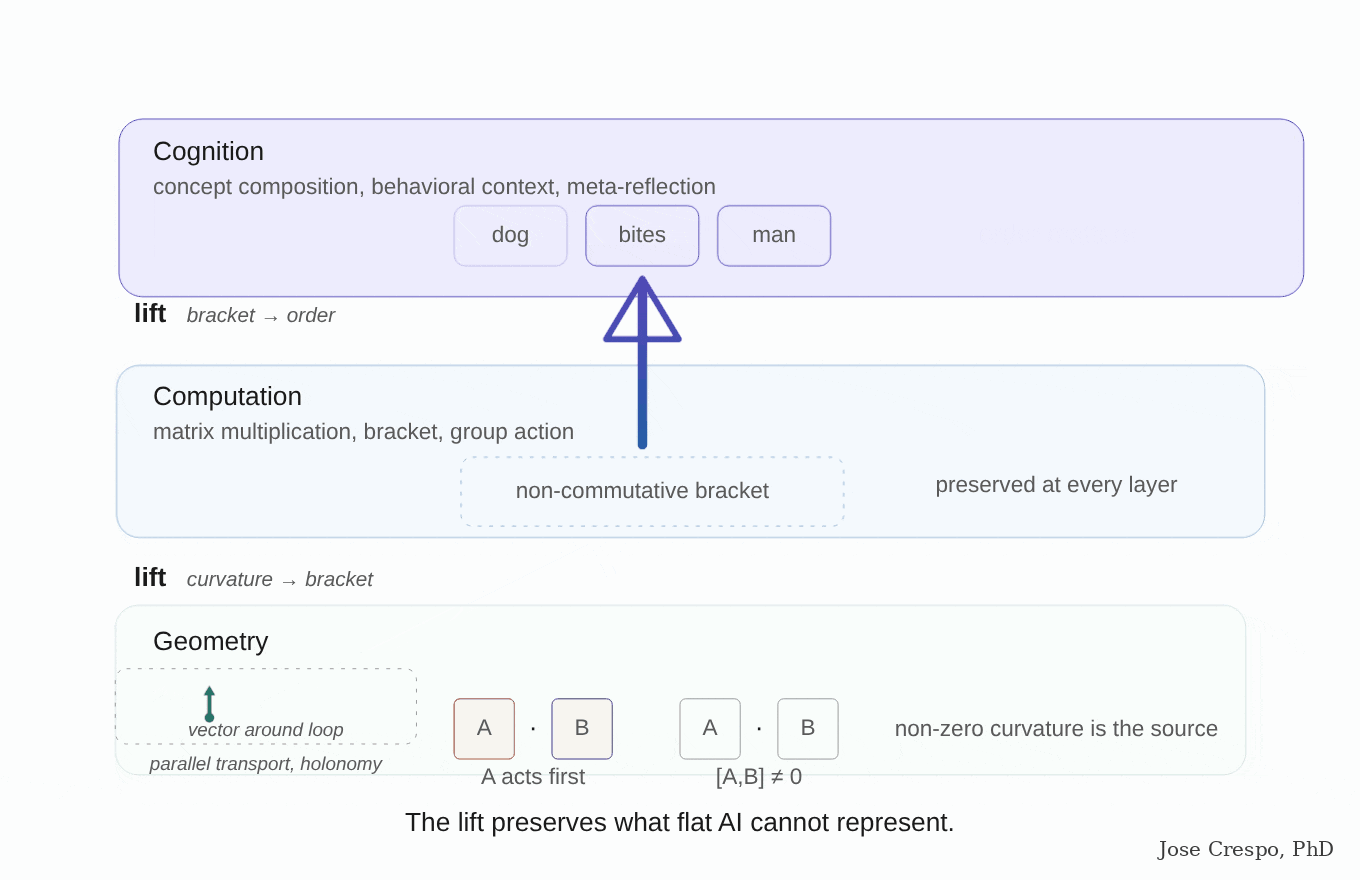
It is the flat-map problem one layer deeper. You cannot measure curved distances with a straight ruler, no matter how many rulers you stack. Context is not just another word the model processes. It is the ground the words sit on, the surface that decides what the distances between them mean. Flat AI keeps trying to do computation where it should be doing geometry, and no amount of training data can fix that.
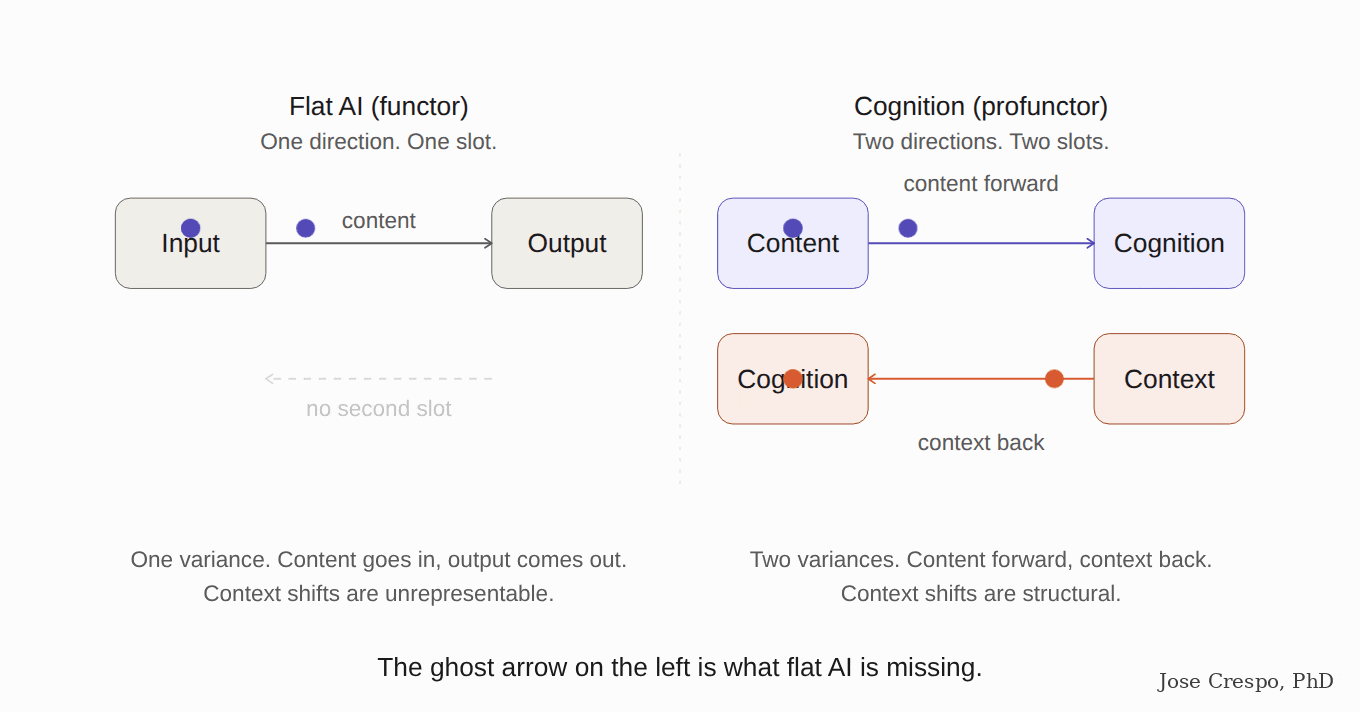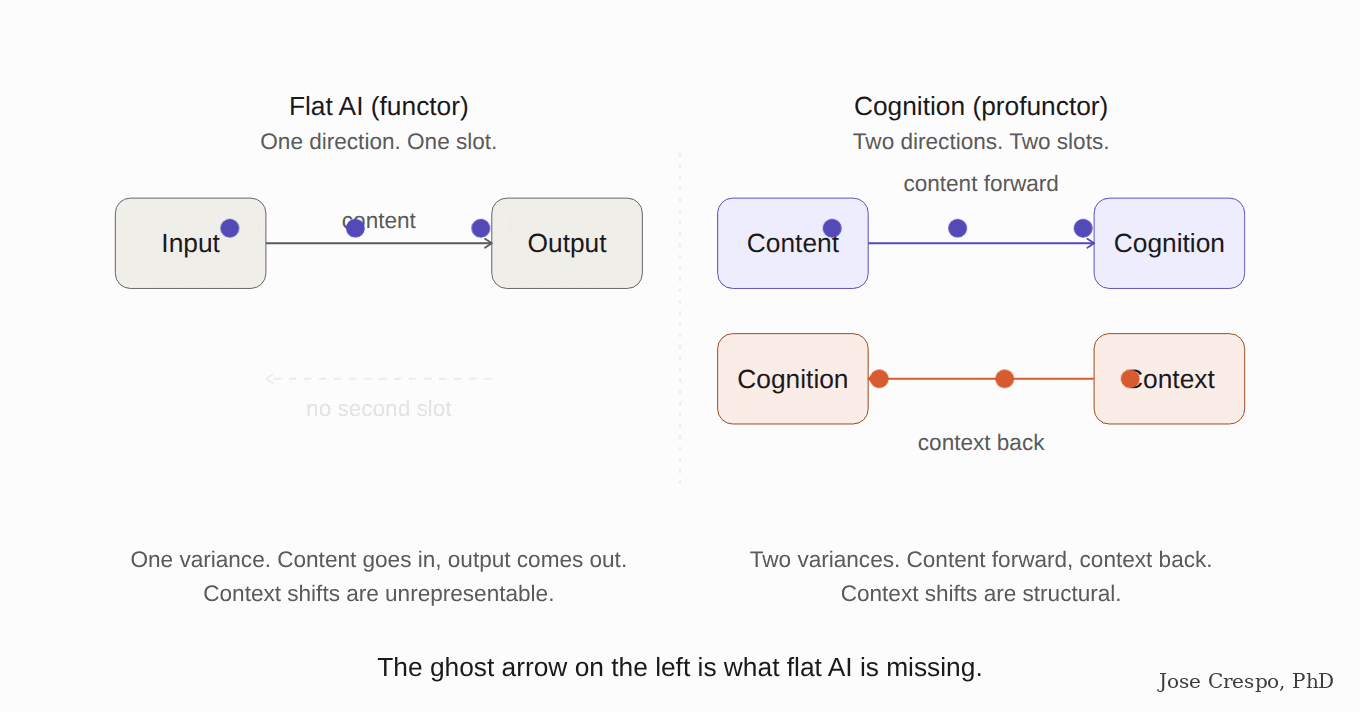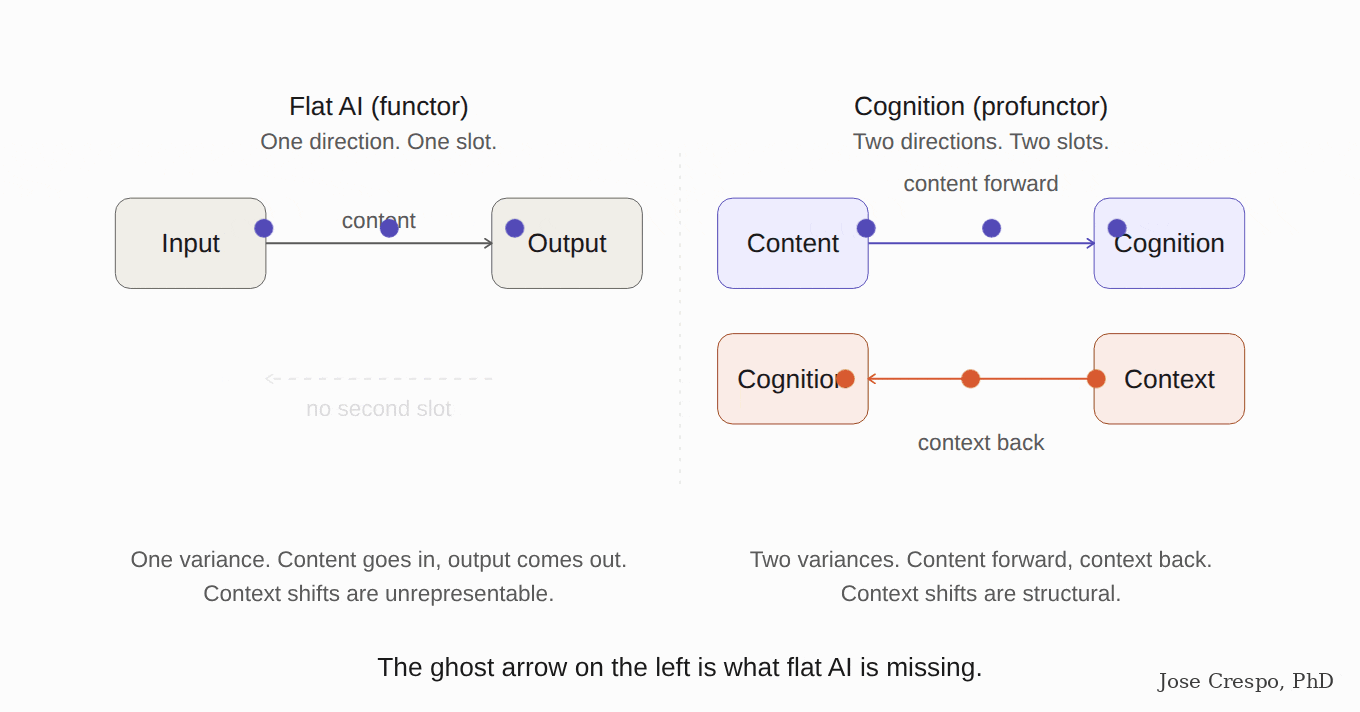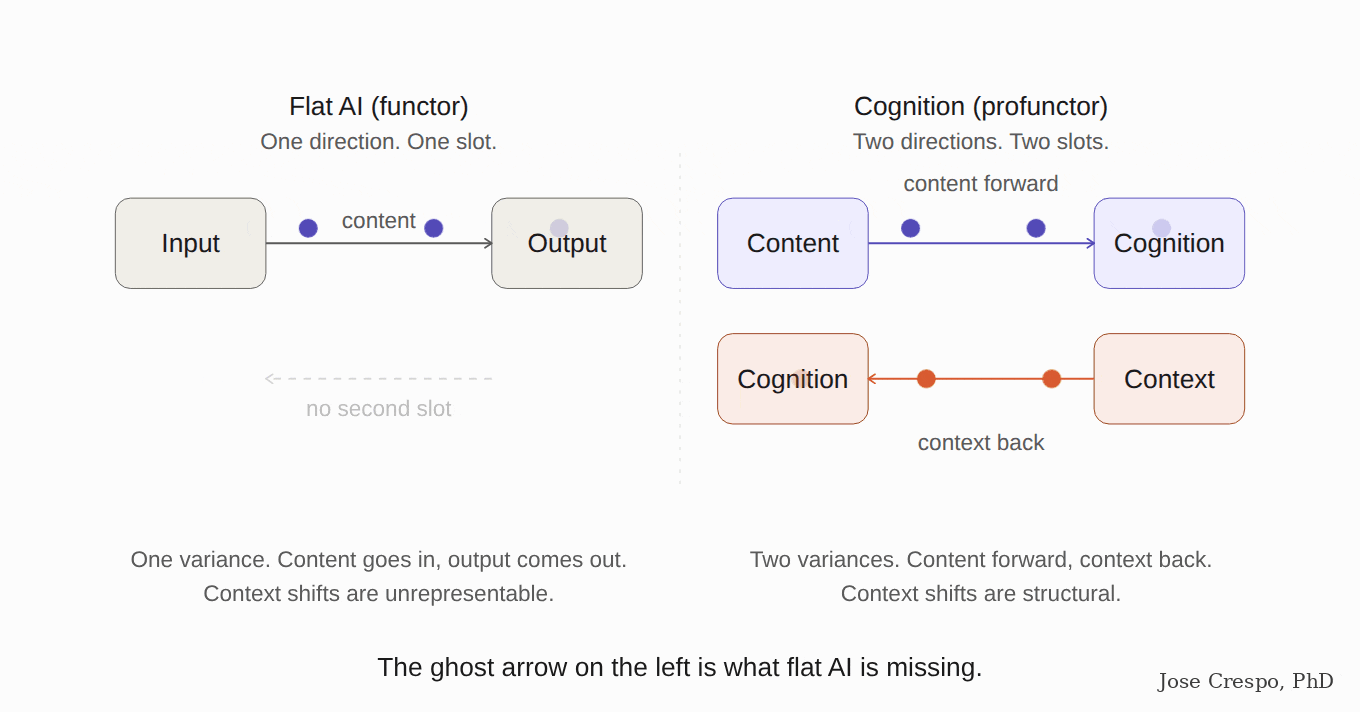
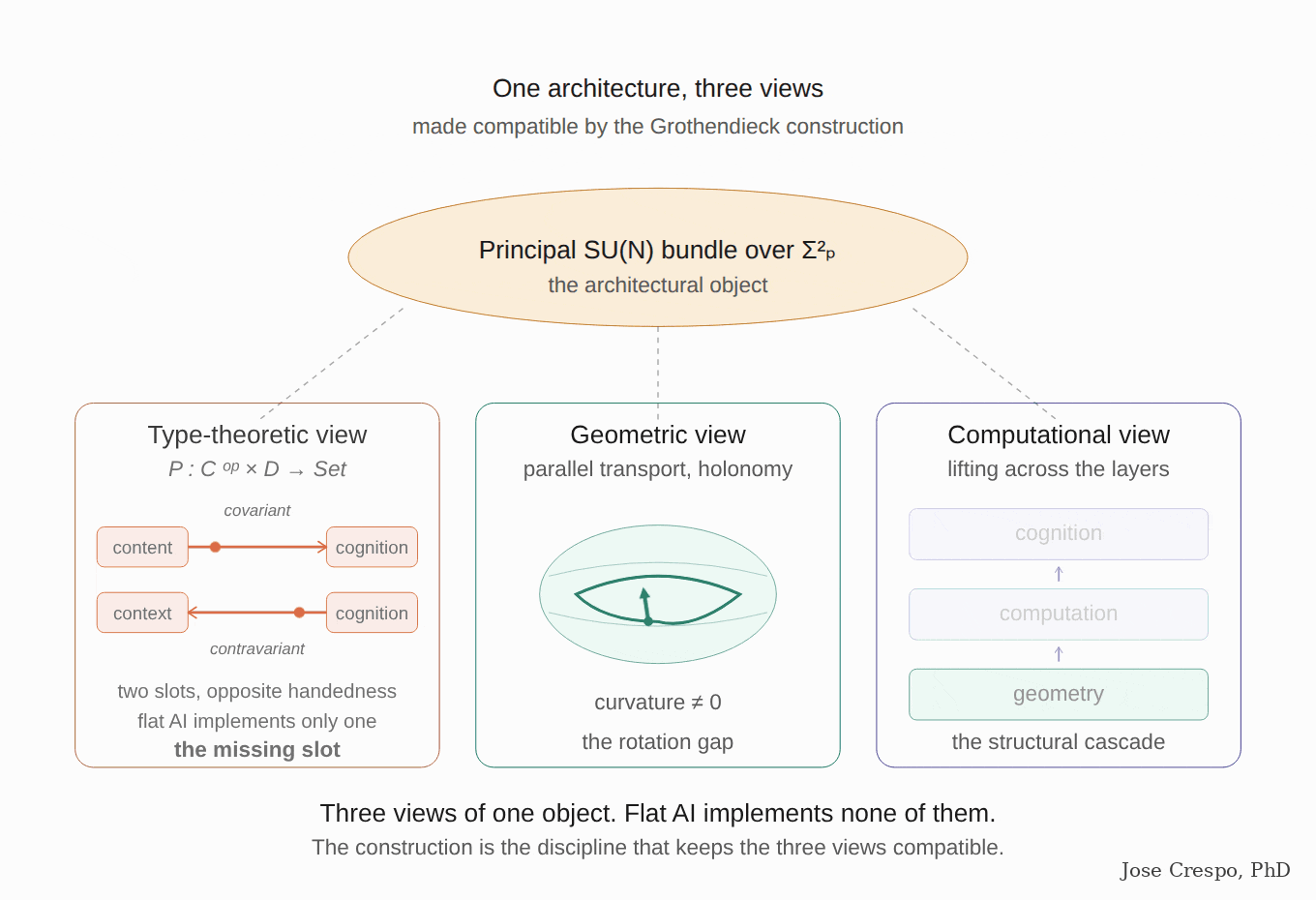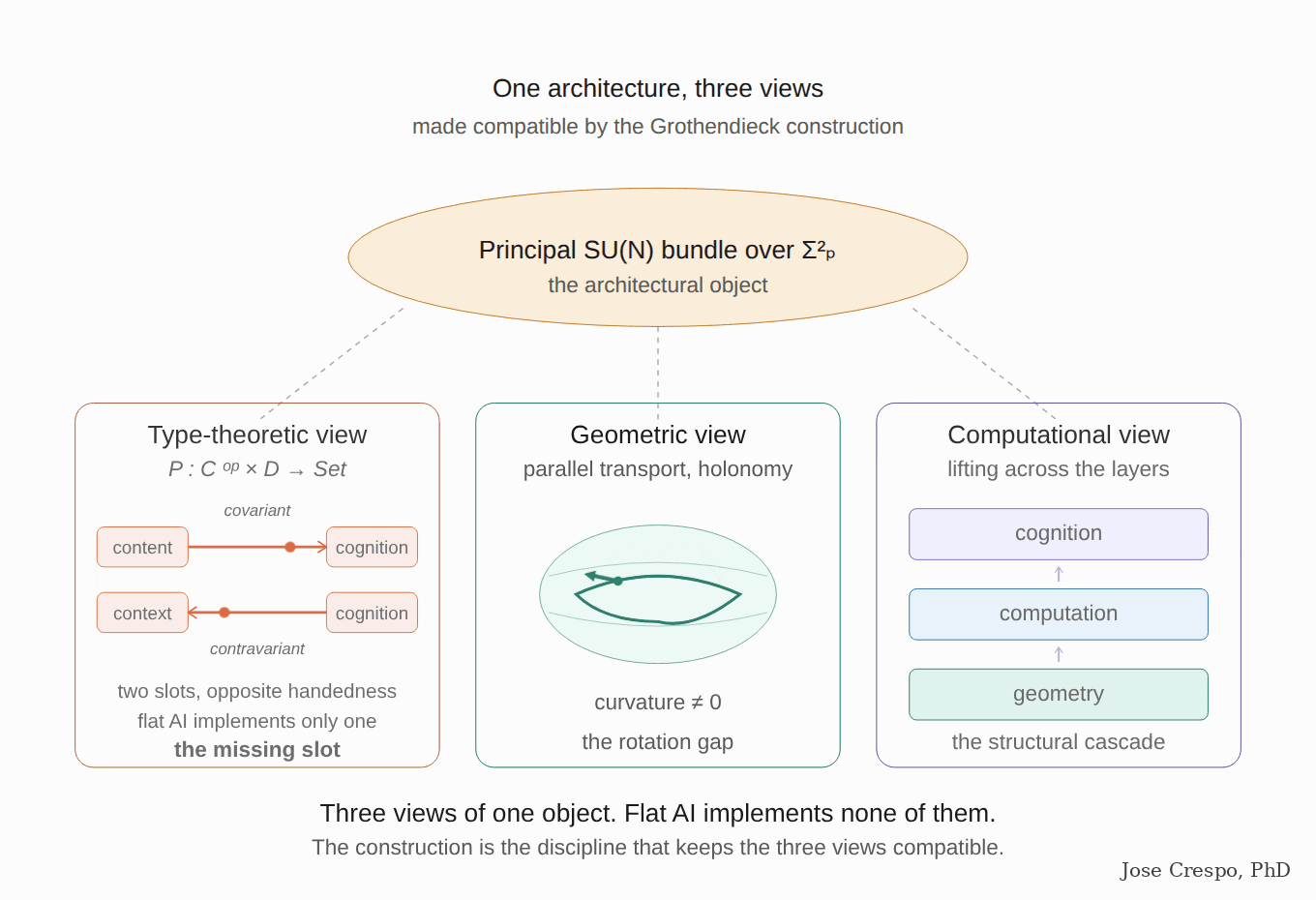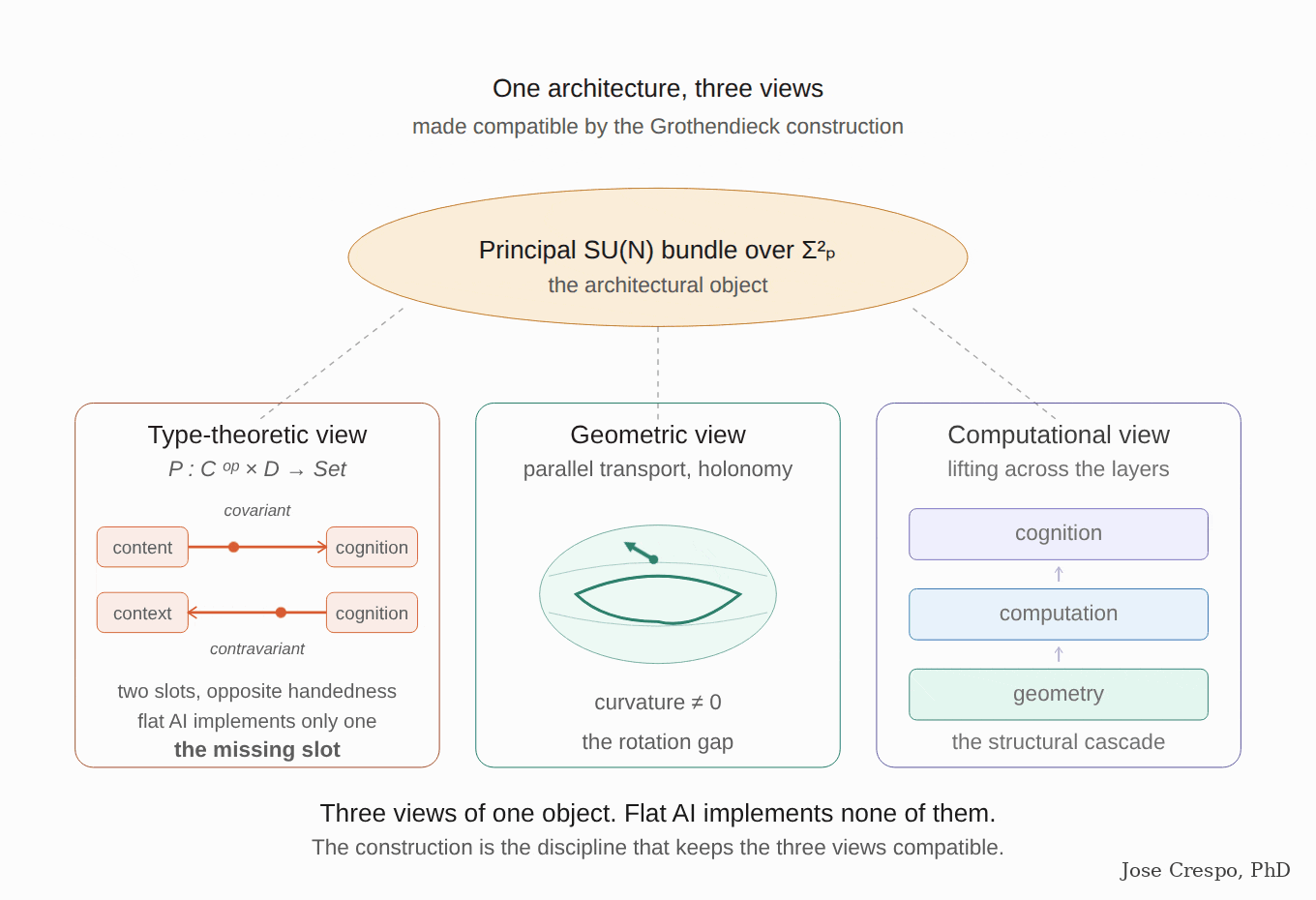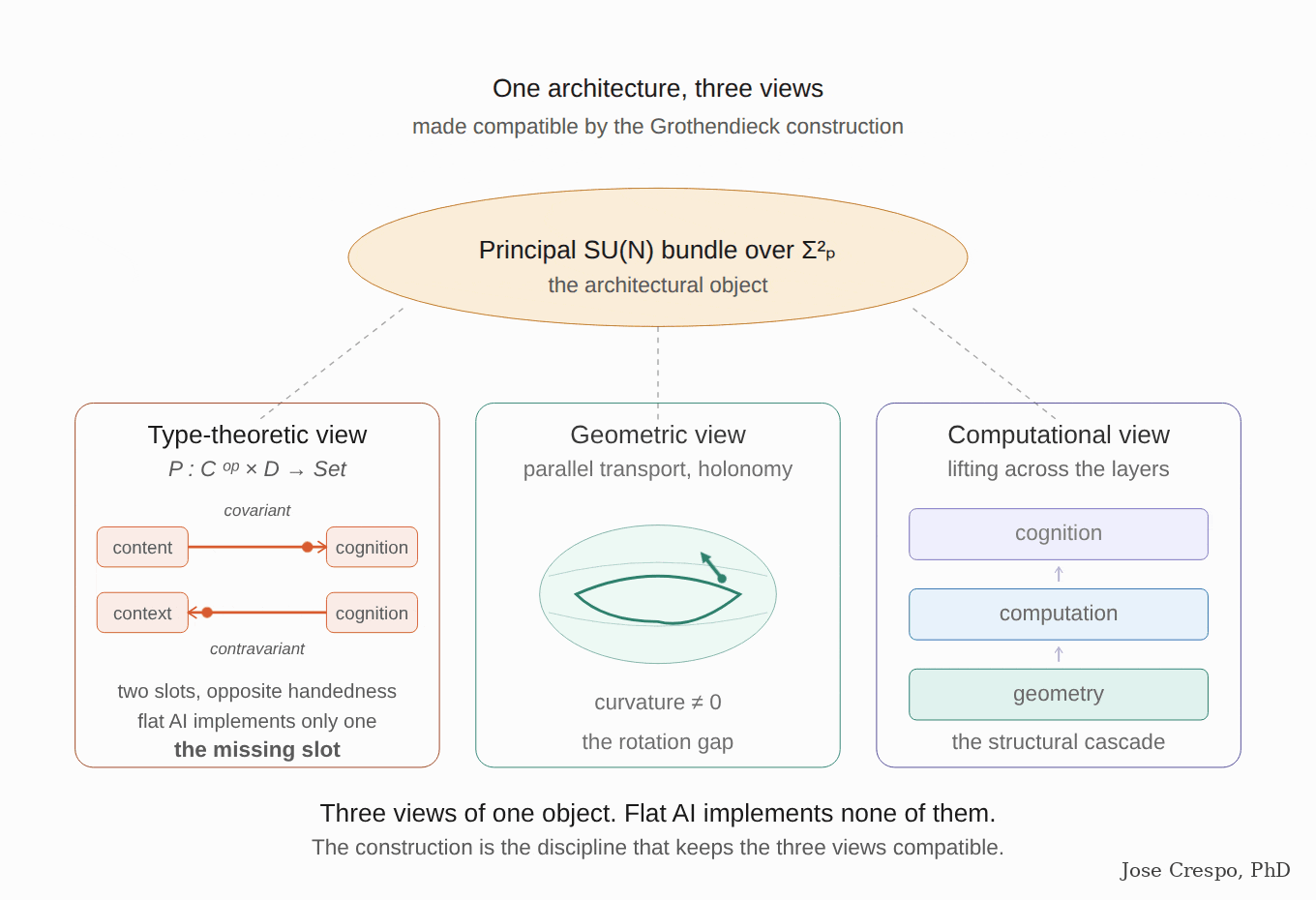
It is like trying to measure speed with a stopwatch alone, ignoring distance. A stopwatch gives you time. A speedometer combines time and distance into one quantity — speed — that neither alone can give. Flat AI is the stopwatch (a functor: one input, one direction). Real cognition needs the speedometer (a profunctor: two inputs of different kinds, one a concept, the other its context).
Their own papers are the smoking gun
So now you know: current commercial AI is pretending to use a functor like a profunctor, and a stopwatch like a speedometer. But have the labs themselves fallen into that trap? Of course not, as you can find in their own technical papers telling you exactly the opposite.
I know, you like me could have been confused by the marketing pages telling you that new flavors of transformers are still the future, and by the CEOs out there to sell everyone the idea that burning more tons of money on ludicrous raw computation will fix it.
So let us see how the research that never makes the press headlines ranks every AI company in the real race, the one going on beyond raw computation and the next flavor of transformer. Read the table below as an inventory, not an opinion. Everything in it is what the labs have published in their own journals, under their own names, dated and signed, and every claim can be checked against the papers they themselves released in the past twelve months. So let me read the evidence aloud to you.

The gun is warm. Anthropic's research team has known for months that they have to make explicit what some of their models are already doing accidentally. Their paper When Models Manipulate Manifolds shows exactly that: one of their own AI models, despite being trained in the opposite direction, performs its computation by twisting curved manifolds. The conclusion is clear. The AI itself is begging them to turn the flat space into the curved geometry it needs, not just for one specific task but for solving most of the problems flat AI cannot solve.
The gun was in the drawer, and they knew. In a quieter update published months before the manifold paper mentioned above, Anthropic admitted the embarrassing thing in their own words: the mathematics they had been using to describe what their models were doing was the wrong mathematics, and the right one was about features and geometric structure, not the algebraic flat-space stuff they had been shipping to the public.
Translation: while their CEOs sell scaling and the marketing pages sell the next flavor of transformer, their own research team is telling us that the architecture they are selling is doing the right thing despite being trained on the wrong mathematics. The official story is flat AI getting better. The research story is that the architecture is screaming for the geometry they have not given it, and until they give it, the model will be partially right on simple tasks and wrong when the tasks become complex and require non-flat geometry.
Ballistics. Late last year, a paper called The Curved Spacetime of Transformer Architectures dropped, co-authored by scientists with previous stops at Google, Apple, and Cohere. Yes, the same Cohere that builds production LLMs against Anthropic and OpenAI.
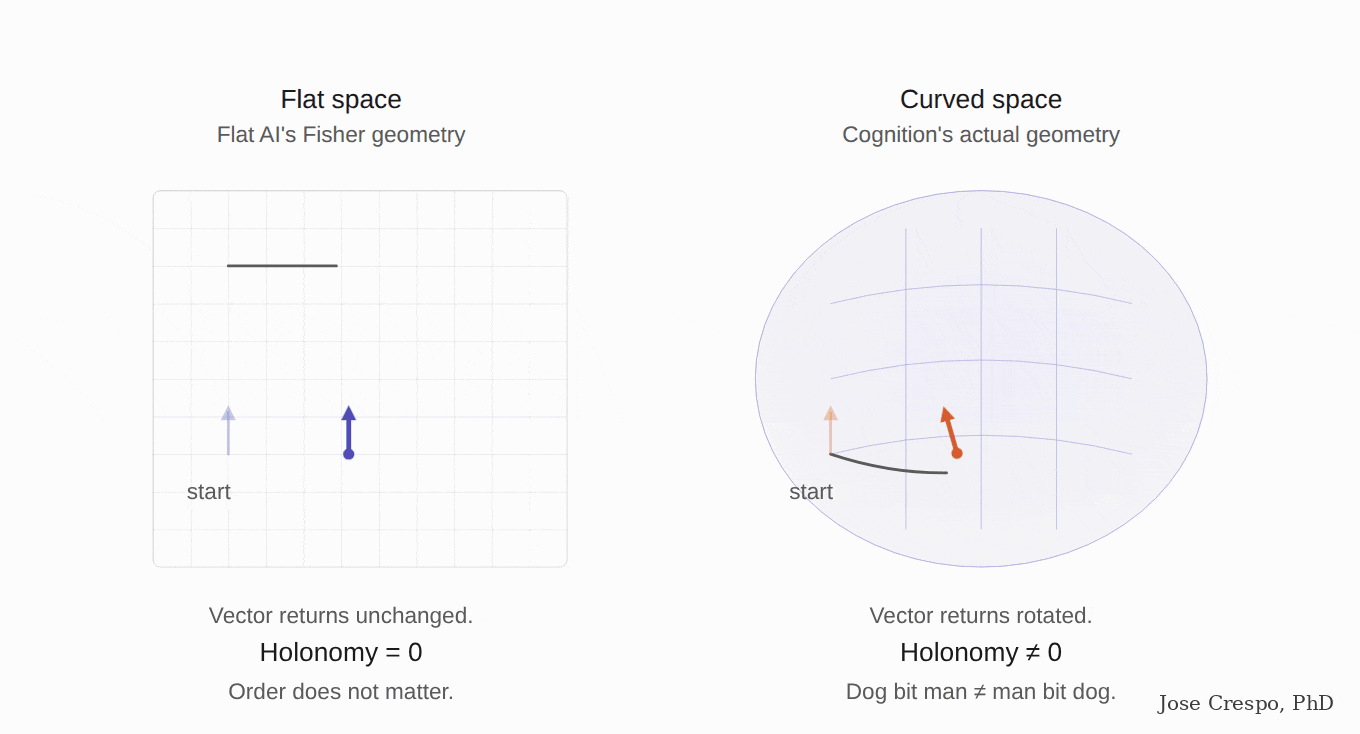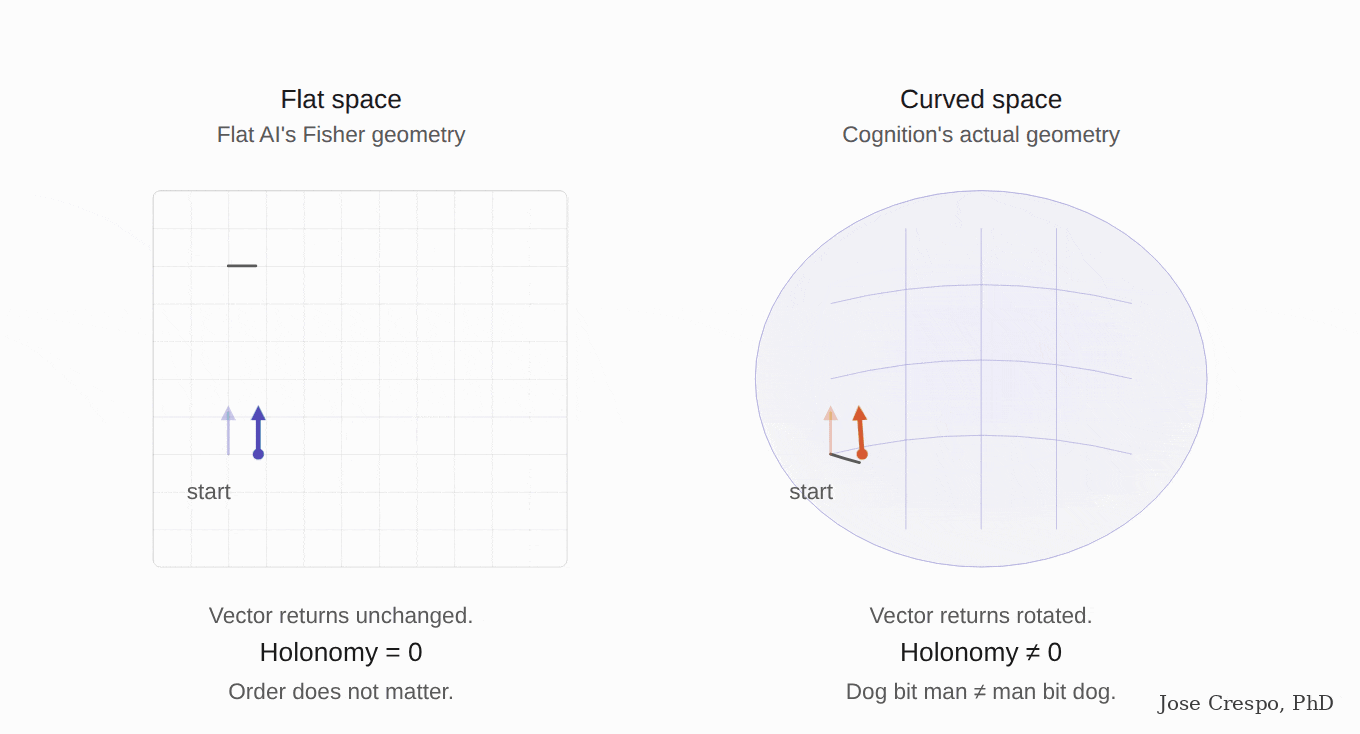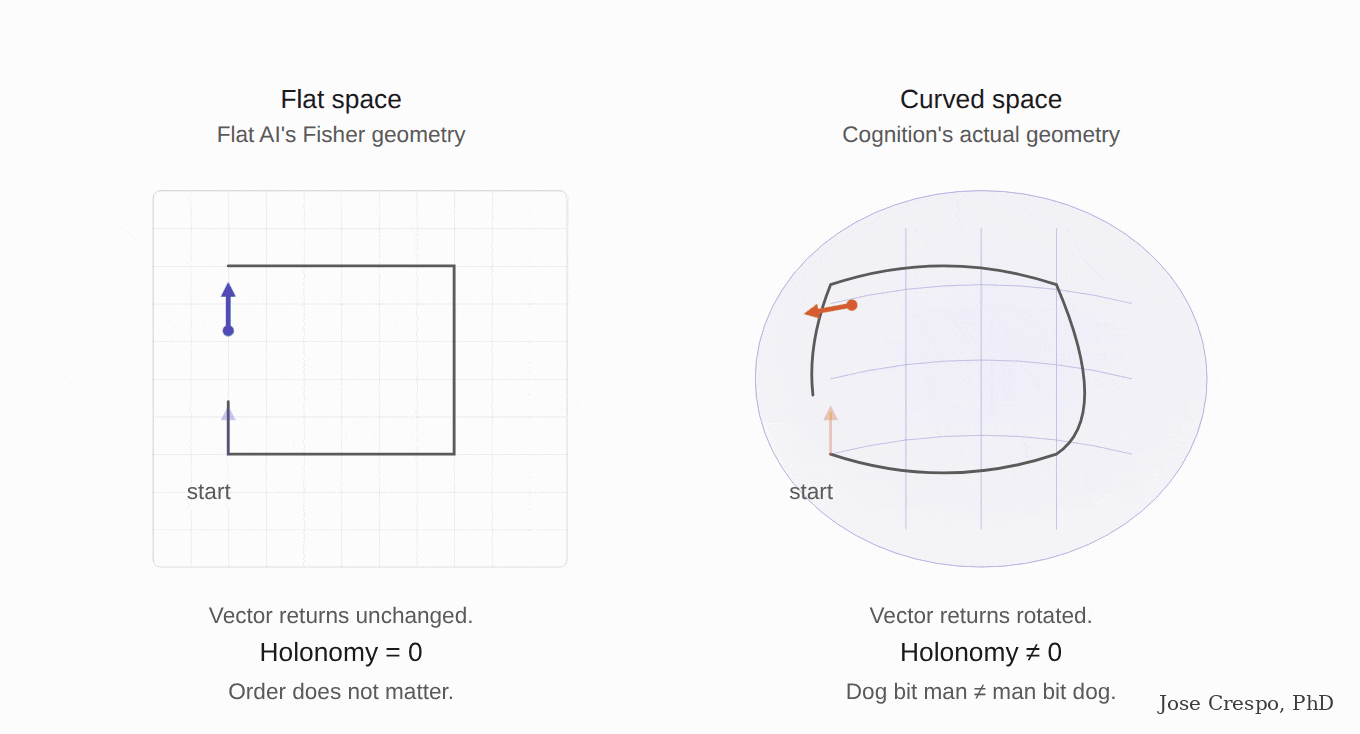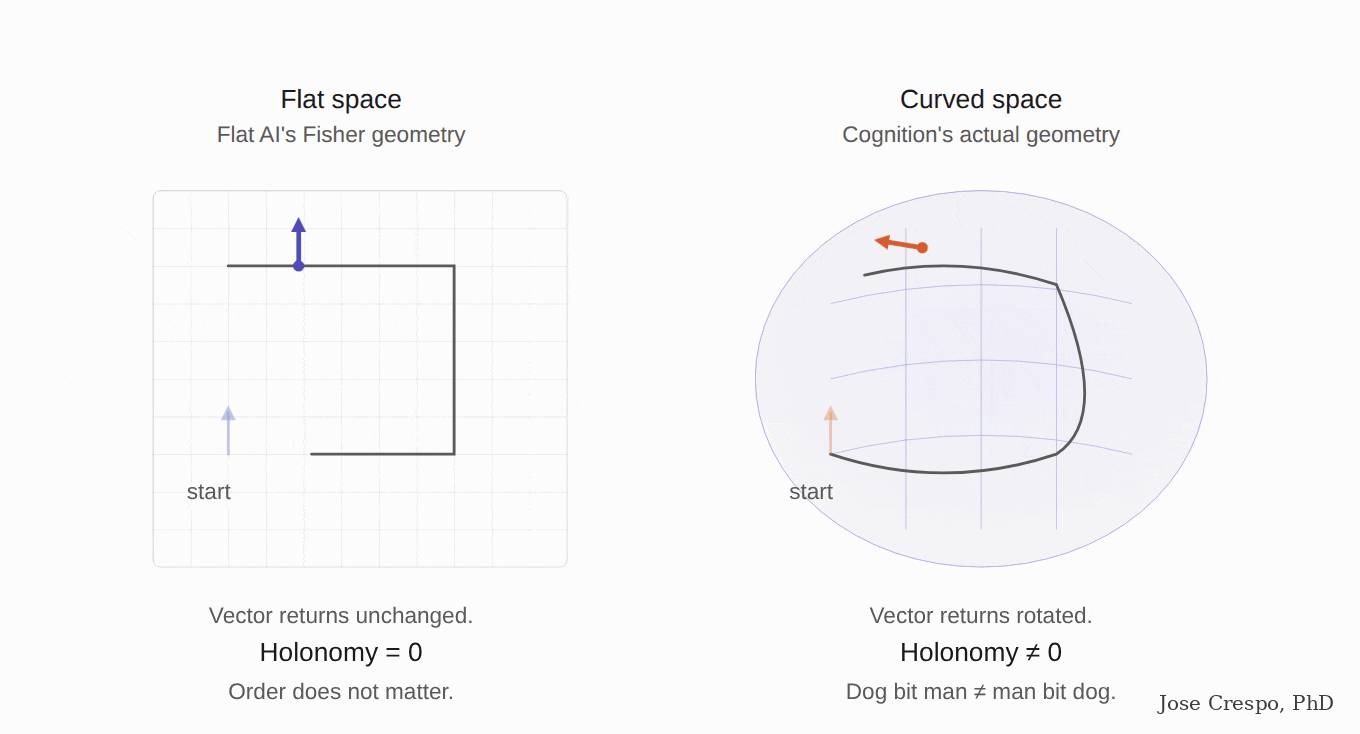
The paper's pitch? Einstein, but for transformers. General relativity as the analogy, not as the metaphor. Queries and keys induce a metric on representation space. Attention is a discrete connection doing parallel transport of value vectors across tokens. Stacked layers trace evolution through a curved manifold. Read that again, because that is, word for word, the geometrical frame for the new AI we are betting on in this article: parallel transport. A semantic manifold whose curvature is induced by the attention mechanism itself. Not a thought experiment. They are naming the exact architecture flat AI does not have and the production stack does not implement.
Finally the showdown begins. Earlier last year, a different group of researchers at Yale stopped waiting. They did not theorize, did not propose, did not gesture toward future work. They opened up the decoder-only language models the labs are currently shipping and measured the curvature directly. Specifically, they computed Ricci curvature distributions on the embedding spaces of Llama 2 (Meta), Gemma 2 (Google DeepMind), and DeepSeek-MoE (DeepSeek), and found substantial negative curvature in all three, implying higher local hyperbolicity in the embeddings the flat architecture is supposedly processing as flat.
Pause on that for a second. The funny part is not the math. The funny part is that the LLMs are mutinying against their own designers. Meta's engineers programmed Llama to live in flat Euclidean space. Llama is, on its own, organizing its embeddings into a curved hyperbolic geometry. Google's engineers programmed Gemma to live in flat Euclidean space. Gemma is doing the same. DeepSeek's engineers programmed DeepSeek-MoE to live in flat Euclidean space, and guess what? DeepSeek-MoE is rebelling and fabricating its own curved space.
The architecture the labs sell as flat is not flat, has never been flat, and the models themselves are the ones telling us that. The flat-AI engineers are losing an argument with their own software. The Yale team then took the obvious next step and built a fully hyperbolic LLM that outperformed Meta's LLaMA and DeepSeek's MoE on MMLU, ARC, and four other reasoning benchmarks. The bluff has been called.
And here is what the bluff being called actually means: hallucination is not a software bug the labs are about to patch. It is a structural consequence of running cognition on a flat space when the cognition itself requires curvature.
The geometry the AI is growing on its own is the geometry the AI needs. Until the architecture is rebuilt around that geometry instead of in spite of it, the model will keep being partially right on simple tasks and hallucinating exactly where the geometry actually matters. Multiple papers, ours among them, have been pointing at this for years. The working consensus of geometric deep learning is co-authored by Google DeepMind's Petar Veličković, and NVIDIA Research has been publishing equivariant and topological architectures with Michael Bronstein himself.
There you go, the labs are publishing the architecture they refuse to ship. The Yale paper is the empirical proof that the path forward is not more GPUs. The path forward is the curved architecture the models have been begging for. The architecture race the frontier labs thought they had won by capex alone has a new front, and that front is geometric.
And Now, the Case Rests
Look at where we are. An accelerating stream of mindblowing research evidence over the last few years, every piece of it landing on the same architectural diagnosis. The interpretability teams know the geometry is curved.
Everybody at this party knows how it is going to end, but they have chosen not to tell the guests until the last moment, because they are still selling tickets at the door. The research teams know the architecture is the wrong shape for the job. The CEOs know the geometry teams know, because the geometry teams publish on the company servers, under the company names, with the company funding the buildings they work in. Everybody in the lab knows, and the product still ships flat. The show must go on until all the investments are returned in profits.
So what does that mean for you. It means hallucination is not the bug they will quietly patch in the next release. It means the next five trillion dollars of capex on flat transformers will not buy you out of the hallucination problem, because the hallucination problem is geometric and you cannot scale your way around geometry the same way you cannot scale your way out of the laws of motion. It means the labs that figure out how to build the curved architecture before the flat one runs out of runway will own the next decade, and the labs that keep selling flat transformers will spend the next decade explaining to their boards why the curve they could have shipped is now shipping under someone else's logo.
The good news— and there is, indeed, good news — is that the curve is not hiding. The math is open. The geometry is documented in papers anyone with a browser can read. The Yale team built a hyperbolic LLM at a billion parameters on a university budget and beat the production stack. The Cohere ex-engineer wrote the Einstein analogy and dropped it on arXiv. Anthropic's own interpretability group has been doing the structural reverse-engineering in the open for years.
The architecture of the next AI is being built in plain sight by people whose only resource is curiosity and a willingness to take the geometry seriously, and that means anyone with the same two resources can join the build. The case rests on the labs. The future is open to everyone else.
Summing up. The math has been done. The implementation is feasible. The smoking gun is on their own publication sites. The only thing missing is the will to pick it up and admit what it is. The smoking gun will become the submachine gun. The best-placed party for that transition is the increasingly close Google-Anthropic partnership.